Malloc Lab 要求用 C 语言编写一个动态存储分配器,即实现 malloc, free 和 realloc 函数。
调试命令如下
./mdriver -V
性能表现主要考虑两点:
- 空间利用率:mm_malloc 或 mm_realloc 函数分配且未被 mm_free 释放的内存与堆的大小的比值。应该找到好的策略使碎片最小化,以使该比率尽可能接近 1
- 吞吐率:每单位时间完成的最大请求数,即要使时间复杂度尽可能小
分数计算公式:
动态内存分配器维护着一个进程的虚拟内存区域,称为堆。如图:
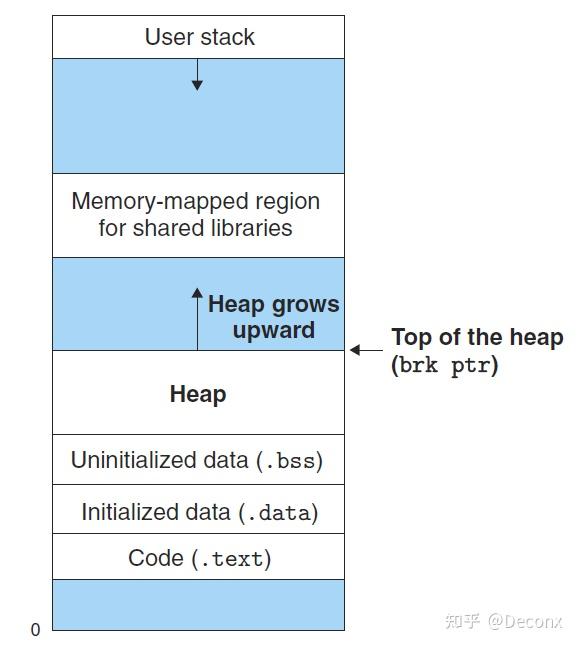
分配器将堆视为一组大小不同的块的集合来维护,且它们的地址是连续的。将块标记为两种,已分配的块供应用程序使用,空闲块用来分配
那么如何实现?翻阅课本能知道作者推荐使用Segregated Free Lists的方法
即在堆的开头,分配数量等于CLASS_SIZE的指针,每个链表中的块有大致相等的大小,分配器维护着一个空闲链表数组,每个大小类一个空闲链表,当需要分配块时只需要在对应的空闲链表中搜索就好了。
不妨以2的幂次分割大小类,由于Free Block最小块大小为16字节(header + prev_p + next_p + footer各4字节)因此从2^4开始划分类别。
为了区分某一空闲块应该被放置在哪个类中,就需要一个select_class函数,通过一个循环函数计算位数进而返回,在此其实可以做进一步的运算优化,介于时间问题暂时没有做。
//根据块大小选择合适的大小类
int select_class(size_t size){
for(int i=4; i<(CLASS_SIZE + 4 - 1); i++){
if(size <= (1 << i)){
return i - 4;
}
}
return CLASS_SIZE - 1;
}在空闲块指针之上,需要分配正常的堆块,翻阅CSAPP教材得知,我们一般通过采取设计序言块(已分配大小为8)+结尾块(已分配大小为0)的方式,方便检验边界情况,当后继块大小为0,则可判断其达到了结尾。
这部分的代码是在mm_init初始化堆的实现的,在此之前需要定义一些宏定义
#define WSIZE 4 //字长大小
#define DSIZE 8 //双字大小
#define CLASS_SIZE 20 //大小类的数量
#define CHUNKSIZE (1<<5) //初始堆大小和扩展堆大小
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc)) //将大小和分配位打包
#define GET(p) (*(unsigned int *)(p)) //将地址p处的值读出
#define GET_HEAD(class) ((unsigned int *)(long)(GET(heap_listp + (class * WSIZE)))) //获取大小类的头指针
#define GET_PREV(bp) ((unsigned int *)(long)(GET(bp))) //找出前序块指针
#define GET_NEXT(bp) ((unsigned int *)(long)(GET((unsigned int*)bp + 1))) //找出后继块指针
#define PUT(p, val) ((*(unsigned int *)(p)) = (val)) //将值val写入地址p处
#define GET_SIZE(p) (GET(p) & ~0x7) //当前块中的block_size读出
#define GET_ALLOC(p) (GET(p) & 0x1) //将当前块中的alloc状态读出
#define HDRP(bp) ((char *)(bp) - WSIZE) //返回块的头部地址
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) //返回块的脚部地址
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE))) //返回下一个块的地址
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE))) //返回上一个块的地址有了以上的宏定义,便可以跟方便的实现mm_init了:
//初始化堆
int mm_init(void)
{
//申请4个字长的空间
if((heap_listp = mem_sbrk((4+CLASS_SIZE)*WSIZE)) == (void *)-1)
return -1;
//申请20个大小类头指针
for(int i = 0; i < CLASS_SIZE; i++) {
PUT(heap_listp + (i * WSIZE), 0);
}
PUT(heap_listp + CLASS_SIZE * WSIZE, 0); //对齐填充
PUT(heap_listp + ((1 + CLASS_SIZE) * WSIZE), PACK(DSIZE, 1)); //序言块头部
PUT(heap_listp + ((2 + CLASS_SIZE) * WSIZE), PACK(DSIZE, 1)); //序言块脚部
PUT(heap_listp + ((3 + CLASS_SIZE) * WSIZE), PACK(0, 1)); //结尾块头部
if(extend_heap(CHUNKSIZE) == NULL)
return -1;
return 0;
}在组织完堆初始化的指针后就可以进行分配栈空间以及一个初始化的空闲块,这部分就会涉及到extend_heap函数:
对于堆扩展,我们调用 mm_sbrk 函数将lab中设计好的抽象 program breaker 上移扩展堆大小,其返回空闲块的头指针,我们设置好它的头尾标记,并通过 coalesce 函数在进行前后空闲块合并之后插入到空闲块链表中。
//扩展堆:words是要扩展的字节数
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
//根据传入的字节数奇偶性来决定是否需要对齐
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
//为bp分配size大小的空间
if((long)(bp = mem_sbrk(size)) == -1)
return NULL;
//初始化新块的头部和脚部
PUT(HDRP(bp), PACK(size, 0)); //free block header
PUT(FTRP(bp), PACK(size, 0)); //free block footer
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); //new epilogue header
//判断前一个块是否是空闲块,如果是则合并
return coalesce(bp);
}合并块的模式包含四种情况,并且在我的设计模式中,在合并后将空闲块插入到空闲链表中去,形成一体化操作。
- Case1: 前后均不空闲
if (prev_alloc && next_alloc) { // case 1: 前后都分配
insert_block(bp);
return bp;
}前后均不空闲的时候就直接插入当前空闲块,并返回bp
- Case2: 后空闲
else if (prev_alloc && !next_alloc) { // case 2: 前分配,后未分配
delete_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}后空闲的时候就从空闲链表中删除后方空闲块,并把当前块的头部和后部块的尾部大小设计为扩展后大小 ( 由于 FTRP 中调用了 HDRP,所以先设计HDRP的size之后FTRP能够正确定位到尾部 ) 并且设置空闲块前驱后继指针为NULL做好清理。
- Case3: 前空闲
else if (!prev_alloc && next_alloc) { // case 3: 前未分配,后分配
delete_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
} 前空闲就从空闲链表中删除前方空闲块,并且注意分配的头部标记是前一块的头部标记,其余逻辑和 Case2类似
- Case4: 前后均非空闲
else { // case 4: 前后都未分配
delete_block(PREV_BLKP(bp));
delete_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}前两种的结合,不多赘述
此处引入了从链表中插入和删除空闲块的两个函数。
这是一个比较核心的函数,关乎整个free block的组织结构,在这里我采用的是查找到class后统一插入到链表头。
//插入块,并将块插入到对应的大小类的表头
void insert_block(void *bp) {
size_t size = GET_SIZE(HDRP(bp)); // 获取块大小
int class = select_class(size); // 获取块的大小类
if (GET_HEAD(class) == NULL) {
PUT((unsigned int *)(heap_listp + (class * WSIZE)), (unsigned int)bp);
PUT((unsigned int *)bp, (unsigned int)NULL);
PUT((unsigned int *)(bp + WSIZE), (unsigned int)NULL);
} else {
// 将块的后继指针指向原来的表头
PUT((unsigned int *)(bp + WSIZE), (unsigned int)GET_HEAD(class));
// 将原来的表头的前驱指针指向新块
PUT((unsigned int *)GET_HEAD(class), (unsigned int)bp);
// 将新块的前驱指针置空
PUT((unsigned int *)bp, (unsigned int)NULL);
// 将新块设置为表头
PUT((unsigned int *)(heap_listp + (class * WSIZE)), (unsigned int)bp);
}
}首先获取目标块的size,并根据size获取对应的class,之后通过GET_HEAD宏定义找到该class所对应的链表头指针,如果root指针有指向那么久进行插入,如果root没有指向,则将root指向该目标块。
这里需要注意的bug是指针维护不良问题,正常情况就会分为四种(该class里只有bp一个指针、bp为第一个指针、bp为最后一个指针、bp前后均有指针)
//删除块并清理指针
void delete_block(void *bp) {
size_t size = GET_SIZE(HDRP(bp)); // 获取块大小
int class = select_class(size); // 获取块的大小类
// PREV 和 NEXT 都为空 -> 头节点设为 NULL
if (GET_PREV(bp) == NULL && GET_NEXT(bp) == NULL) {
PUT((heap_listp + (class * WSIZE)), 0);
// PREV 为空,NEXT 不为空 (第一个节点) -> 头节点设为 NEXT
} else if (GET_PREV(bp) == NULL && GET_NEXT(bp) != NULL) {
PUT((heap_listp + (class * WSIZE)), (unsigned int)GET_NEXT(bp));
PUT(GET_NEXT(bp), 0);
// PREV 不为空,NEXT 为空 (最后一个节点) -> PREV 的 NEXT 设为 NULL
} else if (GET_PREV(bp) != NULL && GET_NEXT(bp) == NULL) {
PUT((GET_PREV(bp) + 1), 0);
}
// PREV 和 NEXT 都不为空 -> PREV 的 NEXT 设为 NEXT,NEXT 的 PREV 设为 PREV
else {
PUT((GET_PREV(bp) + 1), (unsigned int)GET_NEXT(bp));
PUT(GET_NEXT(bp), (unsigned int)GET_PREV(bp));
}
}分割空闲块要考虑剩下的空间是否足够放置头部和脚部
//分离空闲块
void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp));
delete_block(bp); //删除空闲块
if((csize - asize) >= (2 * DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp); //指向剩余的空闲块
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
insert_block(bp); //插入新的空闲块
}
//如果剩余块的大小小于2*DSIZE,则不分离(保证对齐)
else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}最后就是主体部分 mm_malloc 函数,对申请的空间大小按 8 对齐进行舍入,然后根据放置策略查找有无合适的空闲块,如果没有则申请扩展堆,之后逻辑就是通过 find_fit 在空闲链表中寻找适配,如果没找到适配就进行 heap_extend,每次最小扩展 CHUNKSIZE bytes,这里我将 CHUNKSIZE 设为 16。最后放置空闲块,使用place函数进行分配和分割。
void *mm_malloc(size_t size) {
size_t asize; // 调整后的块大小
size_t extendsize; // 扩展堆大小
char *bp;
if (size == 0)
return NULL;
if (size <= DSIZE)
asize = 2 * DSIZE;
else
asize = DSIZE * ((size + DSIZE + DSIZE - 1) / DSIZE);
if ((bp = find_fit(asize)) != NULL) {
place(bp, asize);
return bp;
}
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}我使用的是简单的首次适配,即从小到大遍历分离空闲链表,找到第一块适合的空闲块。如果找不到则切换到下一个更大的class内寻找,如果都找不到就扩展堆
void *find_fit(size_t asize) {
int class = select_class(asize);
unsigned int *bp;
// 如果找不到合适的块,那么就搜索下一个更大的大小类
while (class < CLASS_SIZE) {
bp = GET_HEAD(class); // 获取当前大小类的头指针
// 不为空则寻找
while (bp) {
if (GET_SIZE(HDRP(bp)) >= asize) {
return (void *)bp;
}
// 用后继找下一块
bp = GET_NEXT(bp); // 强制转换为 unsigned int *
}
// 找不到则进入下一个大小类
class++;
}
return NULL;
}直接设置空闲,并释放同时合并
void mm_free(void *ptr) {
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
coalesce(ptr);
}受限于时间,这里的realloc就是简单的写了一份,后面如果有时间就再优化吧。
void *mm_realloc(void *ptr, size_t size)
{
/* size可能为0,则mm_malloc返回NULL */
void *newptr;
size_t copysize;
if((newptr = mm_malloc(size))==NULL)
return 0;
copysize = GET_SIZE(HDRP(ptr));
if(size < copysize)
copysize = size;
memcpy(newptr, ptr, copysize);
mm_free(ptr);
return newptr;
}代码中为了 DEBUG 定义了大量 debug util 函数和 Error Handler,如果想清晰的看清楚堆块的组织结构,调用它们是很有帮助的。还有 debug 要善用 gdb...
同时本次Lab还实现了在vscode内直接可视化调用gdb,调试效率大幅提高。
86/100的分数还算可以接受。
-
这个Lab前前后后一共花了我三四天的时间,相较于前面的四个Lab来说是有一定难度,特别在指针的调用类型、前后的对齐等等细节要求很严格,稍有不慎就会产生错误,我整个周末几乎都在与 segmentation fault 打交道,随意一个小笔误就要找几个小时,唉。
-
CSAPP 课本编排的很有意思,Implict Free List 花费了大量篇幅讲解,给出了所有代码,而后面的 Segregated Free Lists 却几乎是一笔带过。现在做完了实验才知道,原来是要把这部分放进实验考察,果然读 CSAPP 一定要做实验,两者是相得益彰的。
-
犹记得周四下午五点,在被 segmentation fault 折腾的万念俱灰的我又一次编译运行,发现程序跑通时的欣喜若狂,那一刻,仿佛整个世界都是我的,或许,这就是计算机人的浪漫吧。
-
我的实现还有很多可以优化的地方,比如我没有重新实现
realloc函数,空闲块的也可以用更加高效的平衡树来组织。但总体而言还是很好玩的一个Lab,如果不是临近期末DDL有点多。待ddl以后肯定要尝试进一步优化,尽量做到接近满分~