기계학습을 위해서 구글에서 만든 오픈소스 라이브러리로 텐서플로우에서 계산은 데이터 플로우 그래프로 행해지는데 이때 그래프 각각의 노드는 수식을, **간선은 시스템을 따라 흘러가는 데이터(Tensor)**를 나타냄
Tensor - 텐서플로우의 기본 데이터 구조로 보통 다차원 배열을 지칭
A = tf.constant([1, 2, 3])
B = tf.constant([3, 4, 5])tf.constant() - 상수 텐서를 생성
- dtype - 텐서 원소들의 타입
- shape - 결과값 텐서의 차원
- name - 텐서의 명칭
W = tf.Variable(tf.random.normal([1]), name="weight")
# tf.random.normal() - 정규분포를 따르고 크기에 맞는 난수를 생성 tf.Variable - 텐서 변수를 생성**(변수는 상수와 다르게 초기화를 해줘야 함)**
tf.global_variables_initializer() - 여러 변수들을 한번에 초기화시킴
X = tf.placeholder(tf.float32)
sess.run([cost, W, b, train], feed_dict={X: [1, 2, 3, 4, 5]})
# feed_dict를 이용해서 X에 값을 줌tf.placeholder() - 변수의 타입을 미리 설정해놓고 필요한 변수를 나중에 받아서 실행
손실함수(평균제곱오차)
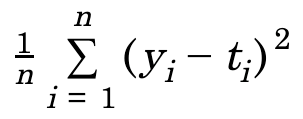
import tensorflow as tf
x_train = [1, 2, 3]
y_train = [1, 2, 3]
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W = tf.Variable(tf.random.normal([1]), name="weight")
b = tf.Variable(tf.random.normal([1]), name="bias")
hypothesis = X * W + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# 추론한 값과 정답 레이블의 차를 제곱하고 평균을 냄
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
# 학습률 0.01로 경사하강법 적용
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
_, cost_val, W_val, b_val = sess.run([train, cost, W, b], feed_dict={X: x_train, Y: y_train})
if step % 20 == 0:
print(step, cost_val)
if step == 2000:
print("W: ", W_val, "b: ", b_val)tf.Session() - tensorflow 연산들을 실행하기 위한 클래스(operation 객체를 실행하고, tensor 객체를 평가하기 위한 환경을 제공하는 객체)
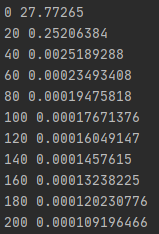
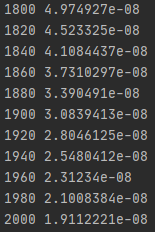
위의 결과를 보면 학습을 반복해서 진행할수록 손실함수의 값이 작아지는 것을 볼 수 있음

결과적으로 2000번 학습을 진행했을때 최적의 가중치와 편향의 값은 위와 같음
import tensorflow as tf
x_data = [[73., 80., 75.], [93., 88., 93.], [89., 91., 90.], [96., 98., 100.], [73., 66., 70.]]
y_data = [[152.], [185.], [180.], [196.], [142.]]
X = tf.placeholder(tf.float32, shape=[None, 3])
# None - 행의 데이터는 원하는 만큼 가능
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([3, 1]), name="weight")
b = tf.Variable(tf.random_normal([1]), name="bias")
hypothesis = tf.matmul(X, W) + b # 행렬 곱
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-5)
train = optimizer.minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for step in range(2001):
cost_val, hy_val, _ = sess.run([cost, hypothesis, train], feed_dict={X: x_data, Y: y_data})
if step % 10 == 0:
print(step, "Cost: ", cost_val, "\nPrediction\n", hy_val)다음과 같은 방법으로 다차원 데이터도 학습이 가능
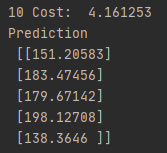
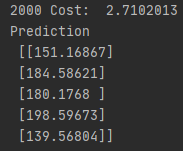
학습을 진행할수록 손실함수의 값이 작아짐과 동시에 예측값이 정답과 유사해지는 것을 볼 수 있음