feat(skill): ship first-party timesfm-forecasting Agent Skill (agentskills.io)#369
Conversation
Add a self-contained AI agent skill for TimesFM that teaches coding agents (Claude Code, OpenCode, Cursor, Codex) how to use the TimesFM API correctly — safe model loading, zero-shot forecasting, covariate workflows, anomaly detection, and the most common pitfalls. Files added: - AGENTS.md — auto-loaded skill document (root of repo) - claude-skill/scripts/check_system.py — mandatory preflight RAM/GPU/disk checker - claude-skill/scripts/forecast_csv.py — CLI wrapper for CSV forecasting - claude-skill/references/ — ForecastConfig API ref, data prep, HW reqs - claude-skill/examples/global-temperature/ — basic forecast + PNG/GIF pipeline - claude-skill/examples/anomaly-detection/ — two-phase detrend+Z-score + quantile PI - claude-skill/examples/covariates-forecasting/ — forecast_with_covariates() XReg demo - .gitattributes — Git LFS rules for PNG/GIF binary outputs Contributed by Clayton Young / Superior Byte Works LLC (@borealBytes) Apache 2.0 — same license as this repository
…ndard
Replace AGENTS.md / claude-skill/ with a proper agentskills.io-compliant
skill directory. Any AI agent that supports the open Agent Skills standard
(Claude Code, OpenCode, Cursor, Codex, etc.) can now install and use this
skill generically.
Changes:
- Remove AGENTS.md (was Claude-specific convention)
- Remove claude-skill/ directory (was Claude-specific naming)
- Add timesfm-forecasting/SKILL.md with compliant frontmatter:
name: timesfm-forecasting
description: ...
license: Apache-2.0
metadata: author, version
- Rename claude-skill/examples/ → timesfm-forecasting/examples/
- Rename claude-skill/scripts/ → timesfm-forecasting/scripts/
- Rename claude-skill/references/ → timesfm-forecasting/references/
- Update .gitattributes paths to match new directory
Skill installs via:
cp -r timesfm-forecasting/ ~/.claude/skills/
cp -r timesfm-forecasting/ ~/.cursor/skills/
# or any agent that supports agentskills.io
Spec: https://agentskills.io/specification
Short pointer for agents working directly in this repo. Points to timesfm-forecasting/SKILL.md and provides install commands for the first-party Agent Skill.
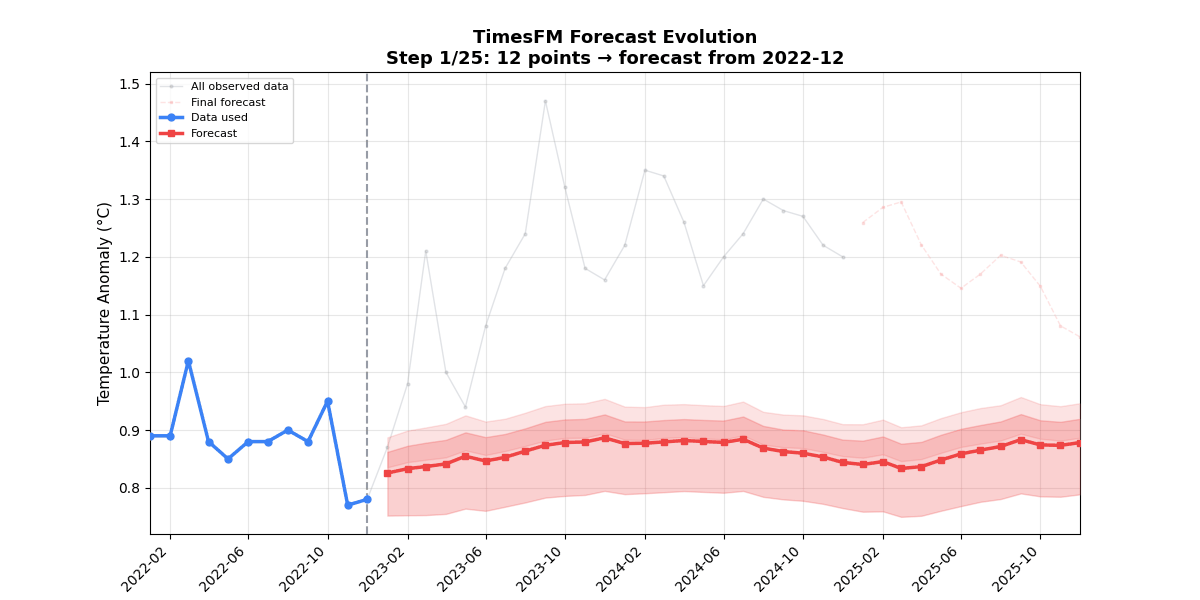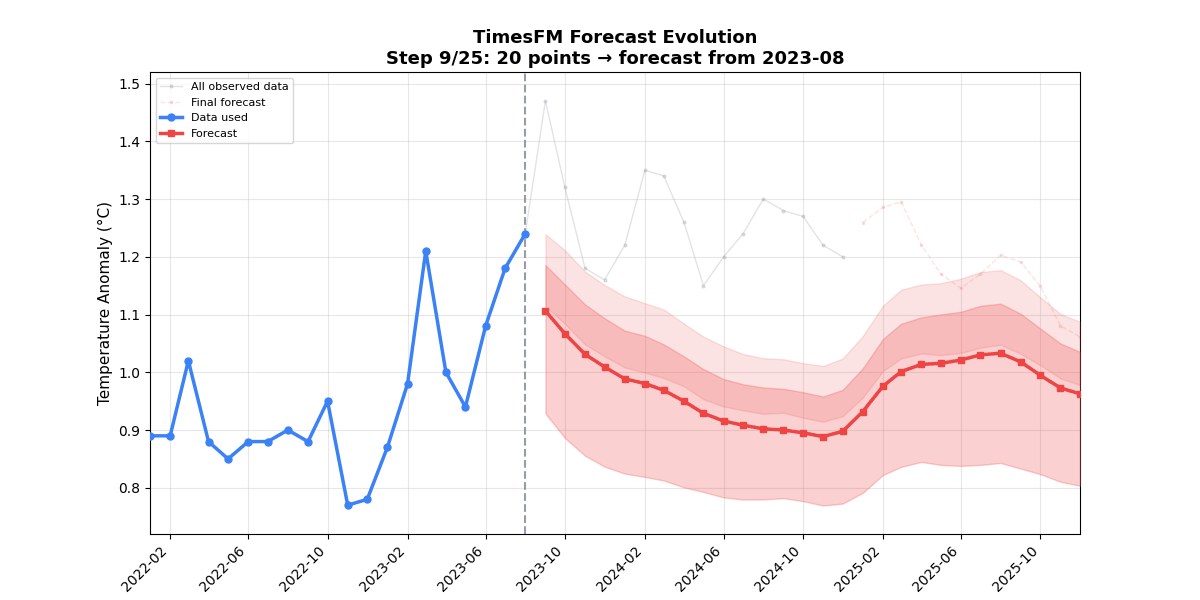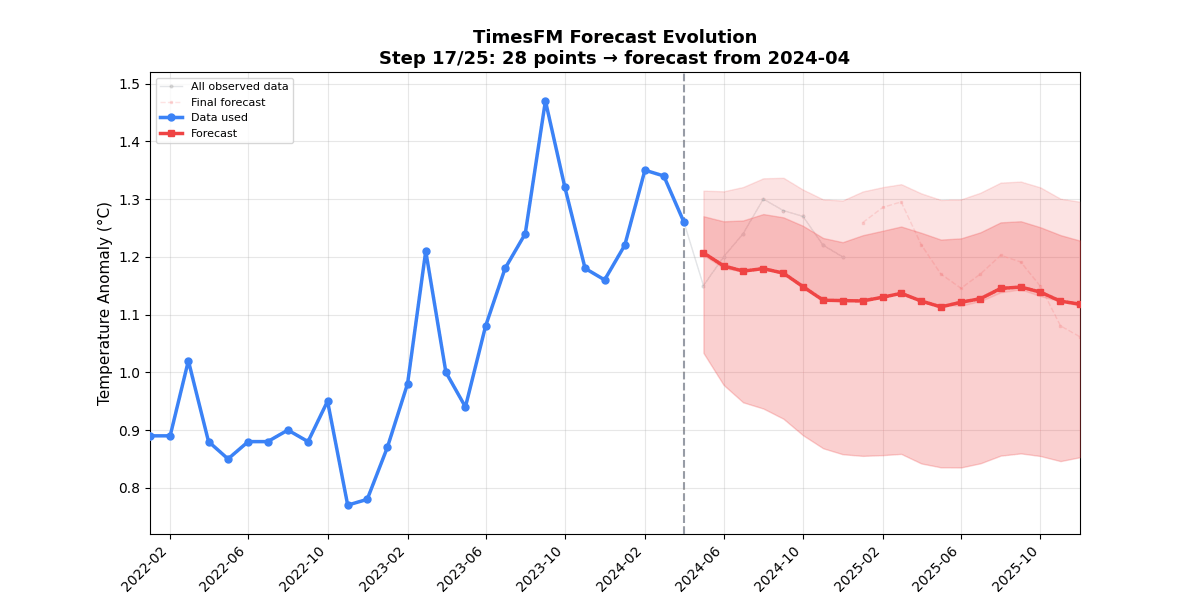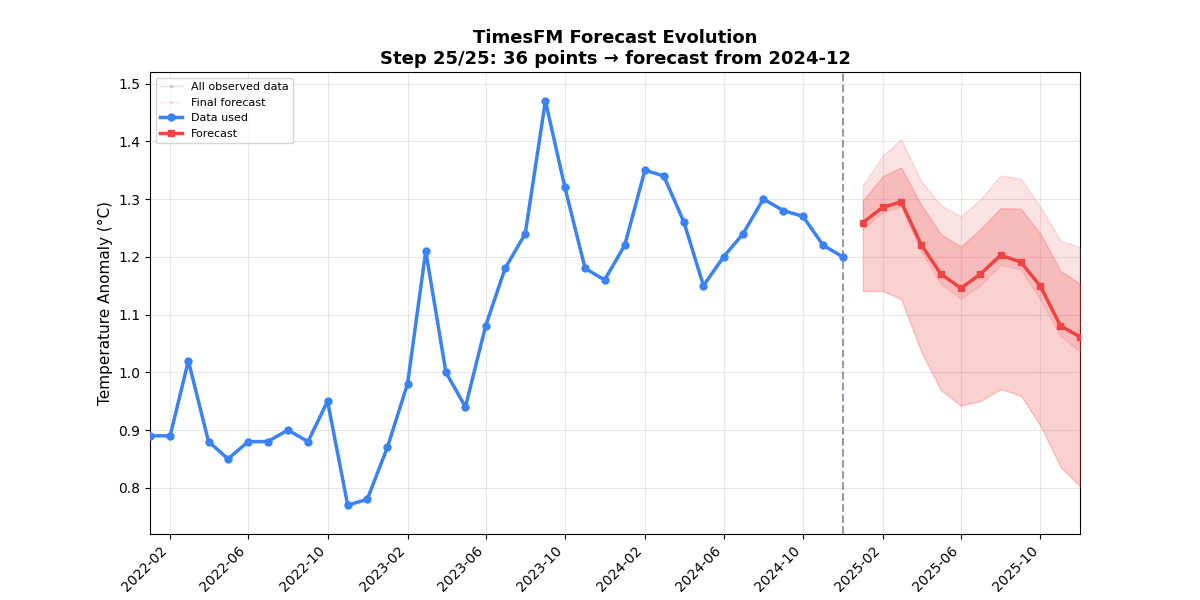
🌡️ Example 1 — Global Temperature Forecast📁 The baseline example. Loads 564 rows of NOAA global temperature anomaly data (2022–2024), runs a zero-shot 12-month forecast with TimesFM 1.0, and outputs a static visualization plus a 25-frame animated GIF showing how the forecast evolves as more historical context is added. 📊 Forecast Visualization
🎬 Forecast Evolution Animation (25 frames)Each frame adds one month of context (12 → 36 months). Watch the forecast tighten as the model sees more of the warming trend.
Key metrics
Run itcd timesfm-forecasting/examples/global-temperature
python run_forecast.py # → output/forecast_output.json
python visualize_forecast.py # → output/forecast_visualization.png
python generate_animation_data.py && python generate_gif.py # → output/forecast_animation.gif |
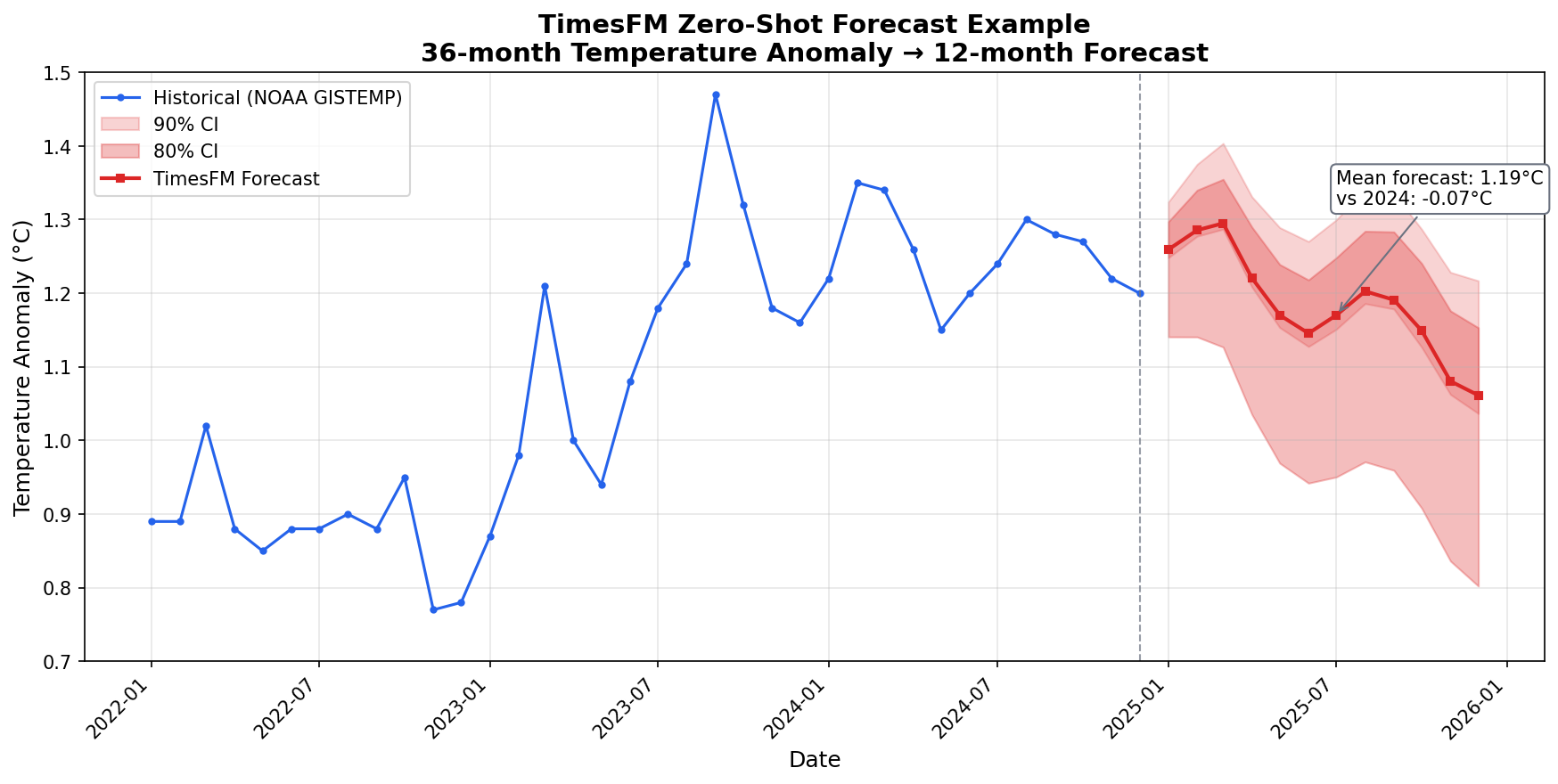
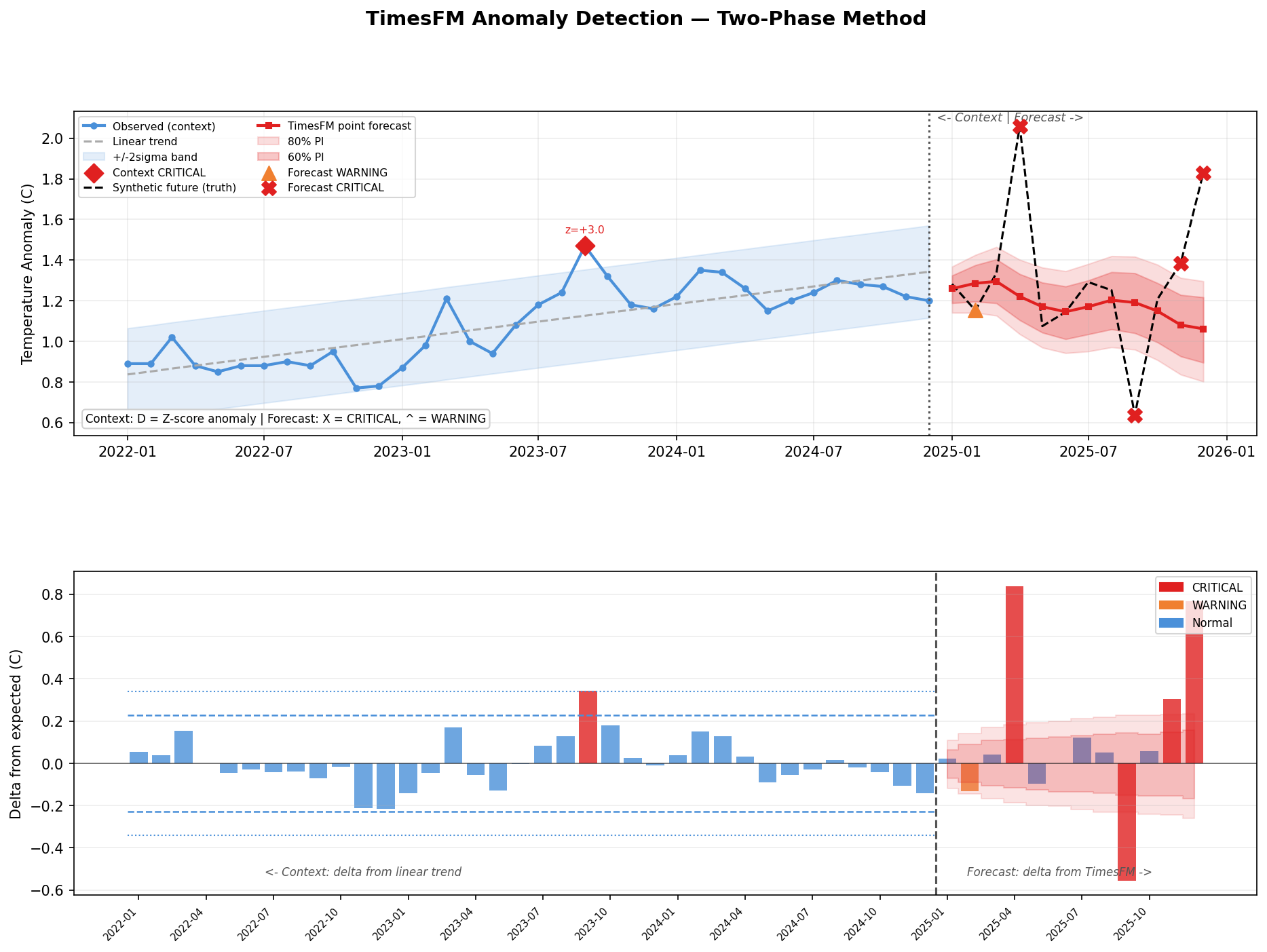
🔍 Example 2 — Anomaly Detection (Two-Phase Method)📁 TimesFM has no built-in anomaly detection, but its calibrated quantile intervals make it a natural fit. This example uses a two-phase approach combining classical detrending with TimesFM's prediction intervals. 📊 Anomaly Detection Output
How it worksPhase 1 — Context (historical 36 months, 2022–2024):
Phase 2 — Forecast (12 months):
Results
Run itcd timesfm-forecasting/examples/anomaly-detection
python detect_anomalies.py
# → output/anomaly_detection.json
# → output/anomaly_detection.png |
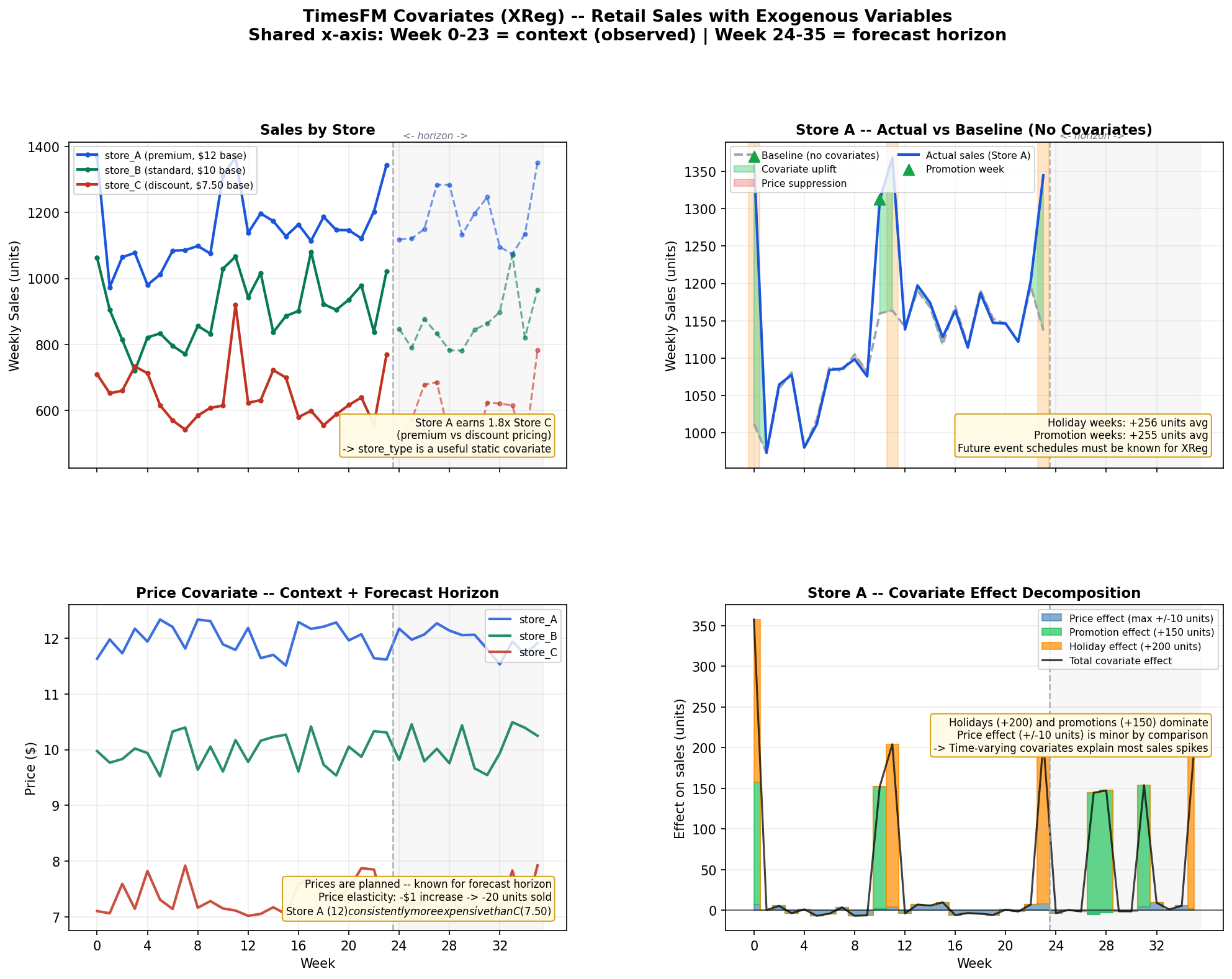
📈 Example 3 — Covariates / XReg Forecasting📁 Demonstrates the 📊 Covariate Decomposition (2×2 layout, shared x-axis)
Dataset
Output CSV: 108 rows (3 stores × 36 weeks = 24 context + 12 horizon) Covariate types used
Run itpip install timesfm[xreg]
cd timesfm-forecasting/examples/covariates-forecasting
python demo_covariates.py
# → output/sales_with_covariates.csv (108 rows)
# → output/covariates_data.png
# → output/covariates_metadata.json |
Why this PR exists — and why it mattersSaw Nic Borensztein's post a couple weeks back and it crystallized something I'd been thinking about:
That's exactly right. Without a skill, agents act sloppily — wrong API calls, wrong quantile indices, OOM crashes on first model load. The documentation exists, but agents don't read it the way humans do. A SKILL.md is the bridge. I'd just submitted a similar skill to K-Dense AI's scientific skills repo — currently the largest collection of research-focused agent skills I can find, covering 140+ scientific Python packages and databases. I was already building skills there (scientific writing standards, markdown/mermaid documentation pipelines), so TimesFM was a natural next addition. But a first-party skill belongs here, not just in a third-party library. The man page analogy is real. Early Linux shipped full documentation with every tool — There's also a security angle nobody talks about: if you don't ship your own skill, someone else will. Third-party skills carry no license provenance, no safety guarantees, no official boundaries for what agents should and shouldn't do with your API. First-party skills let you own that contract. This is me nudging things forward on free trials and leftover credits. Happy to do more — better skills, skill scaling patterns, security/deployment ideas — but I'm running on fumes. Open to a conversation, AI credits, or even just a PR merge or comment from the team. Either way, I hope this is useful. Take it and make it better. — Clayton Young / @borealBytes / Clayton@SuperiorByteWorks.com |
|
@rajatsen91 @siriuz42 — hey, wanted to flag this directly rather than just let it sit in the queue. I only laid eyes on TimesFM yesterday. I pushed through it until the API made sense to me, but I'm not deeply familiar with the model internals and I haven't done this exact forecasting work in a while. For anything going into an official repo, I'd really appreciate a human sanity check on the math before this gets any closer to merge. Specific areas I'd love eyes on:
I'm doing a lot of solo work right now and a real human review from someone who knows this codebase means a lot. Please don't merge until someone's had a proper look. Happy to walk through the logic or answer any questions. Also — if anyone finds this useful and wants to see more, AI credits are genuinely the best way to make that happen. I'm currently grinding on free-tier rate limits and whatever I can piece together — OpenRouter free models, NVIDIA NIM, and OpenCode Zen are my current top three, supplemented by whatever free trials I can find. More credits = better code, more examples, faster turnaround. Any credits from any provider are welcome — I'll put them to work. And if anyone's interested in collaborating or has opportunities — paid or otherwise — feel free to reach out: Clayton@SuperiorByteWorks.com | LinkedIn. Happy to talk. |
| - **Use case**: Light exploration, single-series forecasting, prototyping | ||
| - **Model**: TimesFM 2.5 (200M) only | ||
| - **Batch size**: `per_core_batch_size=4` | ||
| - **Context**: Limit `max_context=512` |
There was a problem hiding this comment.
How did we arrive at this limit? Is it a memory constraint or time constraint ?
 rajatsen91
left a comment
rajatsen91
left a comment
There was a problem hiding this comment.
Thanks a lot. This seems very interesting. Left some minor comments.
| - **Use case**: Batch forecasting (dozens of series), evaluation, production prototypes | ||
| - **Model**: TimesFM 2.5 (200M) | ||
| - **Batch size**: `per_core_batch_size=32` (CPU) or `64` (GPU) | ||
| - **Context**: `max_context=1024` |
| name: timesfm-forecasting | ||
| description: > | ||
| Zero-shot time series forecasting with Google's TimesFM foundation model. Use this | ||
| skill when forecasting ANY univariate time series — sales, sensor readings, stock prices, |
There was a problem hiding this comment.
should this also include description of the xreg mode ?
|
|
||
| Use this skill when: | ||
|
|
||
| - Forecasting **any univariate time series** (sales, demand, sensor, vitals, price, weather) |
There was a problem hiding this comment.
ditto about xreg mode.
…preflight - Add context limit rationale to system_requirements.md with memory formula - Update SKILL.md to include XReg/covariates in description and usage sections - Add dataset-aware memory estimation to check_system.py with new CLI args - Document memory estimation in api_reference.md with Mermaid diagram - Add dataset preflight section to SKILL.md with examples Resolves review comments about: - How context limits (512/1024) were determined - Including XReg mode description in skill documentation Bonus enhancement: Dataset preflight checking prevents OOM before loading data.
|
Thanks for the question! The Rationale:
Memory Formula (now in block-beta
columns 3
ram["Total RAM Required"] model["Model Weights<br/>~0.8 GB"] overhead["Runtime Overhead<br/>~0.5 GB"] buffers["I/O Buffers<br/>~0.2 MB per 1000 series<br/>per 1000 context"]
ram --> model
ram --> overhead
ram --> buffers
Changes made:
The limits are designed to provide a good out-of-box experience on the specified hardware while leaving headroom for actual data processing. |
|
Absolutely! Updated the SKILL.md description to include XReg/covariates as a core capability. Changes made:
The skill now properly presents XReg as a significant capability alongside basic forecasting, while making clear it's an optional advanced feature. |
|
@abhidas @rajatsen91 Happy to answer any other questions from my end. |
|
@siriuz42 can you take a look. Overall looks good to me. |
 siriuz42
left a comment
siriuz42
left a comment
There was a problem hiding this comment.
Hi @borealBytes - It overall looks good! Thanks for the contribution.
My biggest suggestion is to only instruct the agent to use 2.5 - there is little value of using older versions due to quality reasons.
See the detailed comments.
| - You need time series classification or clustering → use `aeon` | ||
| - You need multivariate vector autoregression or Granger causality → use `statsmodels` | ||
| - Your data is tabular (not temporal) → use `scikit-learn` | ||
| - You cannot install optional dependencies → XReg requires scikit-learn and JAX |
There was a problem hiding this comment.
Maybe
You need to run XReg but cannot install optional dependencies → XReg requires scikit-learn and JAX
|
|
||
| hparams = timesfm.TimesFmHparams(horizon_len=HORIZON) | ||
| checkpoint = timesfm.TimesFmCheckpoint( | ||
| huggingface_repo_id="google/timesfm-1.0-200m-pytorch" |
There was a problem hiding this comment.
Wrong version 1.0 --> 2.5, in which case the model initialization code also needs minor revision.
| print(f"\n🤖 Loading TimesFM 1.0 (200M) PyTorch (horizon={MAX_HORIZON})...") | ||
| hparams = timesfm.TimesFmHparams(horizon_len=MAX_HORIZON) | ||
| checkpoint = timesfm.TimesFmCheckpoint( | ||
| huggingface_repo_id="google/timesfm-1.0-200m-pytorch" |
| ```python | ||
| hparams = timesfm.TimesFmHparams(horizon_len=12) | ||
| checkpoint = timesfm.TimesFmCheckpoint( | ||
| huggingface_repo_id="google/timesfm-1.0-200m-pytorch" |
|
|
||
| hparams = timesfm.TimesFmHparams(horizon_len=12) | ||
| checkpoint = timesfm.TimesFmCheckpoint( | ||
| huggingface_repo_id="google/timesfm-1.0-200m-pytorch" |
| | Version | Params | Context | Status | HuggingFace checkpoint | | ||
| | ------- | ------ | ------- | ------ | ---------------------- | | ||
| | **2.5** | 200M | 16,384 | **Latest** | `google/timesfm-2.5-200m-pytorch` | | ||
| | 2.0 | 500M | 2,048 | Archived | `google/timesfm-2.0-500m-pytorch` | |
There was a problem hiding this comment.
Should we emphasize the latest version (2.5) due to quality reasons? I am fine with not referencing 1.0 or 2.0 at all.
|
|
||
| - [ ] **Output shape** — `point_fc` is `(n_series, horizon)`, `quant_fc` is `(n_series, horizon, 10)` | ||
| - [ ] **Quantile indices** — index 0 = mean, 1 = q10 ... 9 = q90. NOT 0 = q0. | ||
| - [ ] **Frequency flag** — TimesFM 1.0/2.0: pass `freq=[0]` for monthly. TimesFM 2.5: omit. |
| upper_80 = q[:, :, 9] # 90th percentile | ||
| median = q[:, :, 5] | ||
| ``` | ||
|
|
There was a problem hiding this comment.
nit: maybe mention the agent can further extrapolate these quantiles using a method of their choice, e.g., half sided Gaussian approximation?
|
Let's merge the PR for now. Let's address the deprecation of v1 in a later PR. |
What this adds
A
timesfm-forecasting/directory — a compliant Agent Skill that teaches AI agents how to use the TimesFM API correctly.Agents that support the open Agent Skills standard (OpenCode, Cursor, Codex, and others) discover and install skills like this:
Once installed, the agent reads
SKILL.mdat startup and gets accurate, production-ready knowledge of the TimesFM API — correct quantile indices, mandatory system check before model load, fullForecastConfigreference — before writing a single line of code.Structure
AGENTS.mdat repo root is a lightweight entry point for agents working directly in this repo (points to the skill and provides install instructions).SKILL.md covers
ForecastConfigparameter reference with "when to change" guidanceNo existing files modified
Everything lives under
timesfm-forecasting/andAGENTS.md. The existingsrc/,v1/,notebooks/, andREADME.mdare untouched.Testing
All three examples verified (see comments below for output images):
examples/global-temperature/point_forecasthas 12 values; PNG shows context + forecast + PI bands; GIF animates 25 framesexamples/anomaly-detection/examples/covariates-forecasting/Regression commands in
SKILL.mdunder Validation & Verification.